Top 10 RAG Frameworks and Platforms for Enterprise in 2026
Enterprise RAG isn't just retrieval. It's what happens after you find the information. Here are 10 RAG frameworks and platforms ranked by what they deliver for enterprise knowledge workflows.
Enterprise RAG (Retrieval-Augmented Generation) frameworks enable AI systems to retrieve relevant information from enterprise data sources before generating responses — combining the reasoning capability of LLMs with access to up-to-date, organization-specific knowledge. First introduced by Lewis et al. in a landmark 2020 NeurIPS paper, RAG has since become the default architecture for enterprise knowledge applications. The global RAG market is projected to reach $40 billion by 2035, with large enterprises now accounting for over 72% of deployments.
But here's the thing most teams discover after their first RAG project: retrieval is the easy part.
Getting an LLM to find the right document and generate a grounded answer is a solved problem. Dozens of frameworks, databases, and platforms handle it well. What's hard is everything that comes after. Validating that the retrieved information is current. Cross-referencing it against data in three other systems. Routing the result to the right person. Handling the exception when the answer is ambiguous. Updating the CRM, triggering the next step, and logging every decision for compliance.
Enterprise knowledge workflows don't end at retrieval. They start there.
This guide ranks 10 RAG frameworks and platforms by how well they serve enterprise use cases, from pure retrieval to full workflow completion. The right choice depends on where your bottleneck actually is.
What is enterprise RAG?
Enterprise RAG is a pattern where an AI system retrieves relevant documents or data from your internal systems — knowledge bases, CRMs, ERPs, communication tools — and uses that retrieved context to generate accurate, grounded responses. Unlike fine-tuning (which bakes knowledge into the model permanently), RAG retrieves information at query time, which means the AI always has access to current, organization-specific knowledge.
The term originated with Patrick Lewis et al.'s 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" at NeurIPS, which showed RAG systems outperforming pure parametric models on knowledge-intensive tasks. In the years since, the pattern has evolved from an academic technique into the production standard for enterprise AI. According to Forrester's 2025 analysis, RAG has become the default architecture for enterprise knowledge assistants.
RAG vs fine-tuning: when to use each
Fine-tuning trains the model's parameters on your data. It's best when the style, format, or domain terminology needs to change, and when the underlying knowledge doesn't update frequently. The limitation: the knowledge becomes stale the moment it's baked in.
RAG retrieves fresh information at query time without modifying the model. It's best when your enterprise knowledge is dynamic (prices, policies, customer records, product catalogs), when you need citations and auditability, or when you want to update knowledge without retraining. Most enterprise knowledge applications need RAG, not fine-tuning — the data changes too fast.
Many production systems use both: RAG for dynamic knowledge retrieval plus fine-tuning for domain-specific response format or terminology.
RAG vs AI agents: what's the difference?
RAG answers the question: "How does the AI get accurate, up-to-date information?" It's a retrieval architecture — the AI fetches relevant context before generating a response.
AI agents answer the question: "What does the AI do with that information?" Agents take actions: they call APIs, update records, trigger workflows, make decisions, and route tasks — not just generate answers.
The distinction matters for enterprise buyers. A RAG-only system surfaces the right information. An agent system acts on it. Most enterprise workflows need both — accurate retrieval plus the ability to execute the downstream steps. This distinction defines the maturity curve described below.
Quick comparison
| Platform | Category | RAG approach | Requires engineering? | Goes beyond retrieval? | Maturity stage | Best for |
|---|---|---|---|---|---|---|
| Nexus | Enterprise agent platform + service | Built-in (real-time + stored RAG) | No (business teams with FDE support) | Yes, full workflow automation | Stage 3 | Enterprises needing AI that acts on knowledge |
| Haystack | Open-source framework | Pipeline-based, highly configurable | Yes | No (retrieval-focused) | Stage 1–2 | Engineering teams building custom RAG applications |
| LangChain | Open-source framework | Flexible, multi-pattern | Yes | Partial (agent capabilities) | Stage 1–2 | Engineering teams building broad LLM applications |
| LlamaIndex | Open-source framework | Data-first, sophisticated indexing | Yes | No (data retrieval focused) | Stage 1–2 | Complex data retrieval and reasoning |
| Glean | Enterprise search platform | Built-in, managed | No | No (search + answers) | Stage 1–2 | Enterprise knowledge search across tools |
| Vectara | RAG-as-a-service | Fully managed pipeline | Minimal | No (QA focused) | Stage 1 | Quick RAG deployment without infrastructure |
| Pinecone | Vector database + RAG | Infrastructure-level | Yes | No (infrastructure) | Stage 1 | Scalable vector search infrastructure |
| Cohere | AI model provider + RAG toolkit | Model-level, enterprise-grade | Yes (moderate) | No (model layer) | Stage 1 | Enterprise embeddings and re-ranking |
| Elasticsearch | Search platform + vector capabilities | Hybrid keyword + semantic | Yes | No (search infrastructure) | Stage 1–2 | Organizations already running Elasticsearch |
| Weaviate | AI-native vector database | Built-in vectorization + generation | Yes | No (database layer) | Stage 1 | AI-native search with built-in modules |
The platforms, ranked
1. Nexus
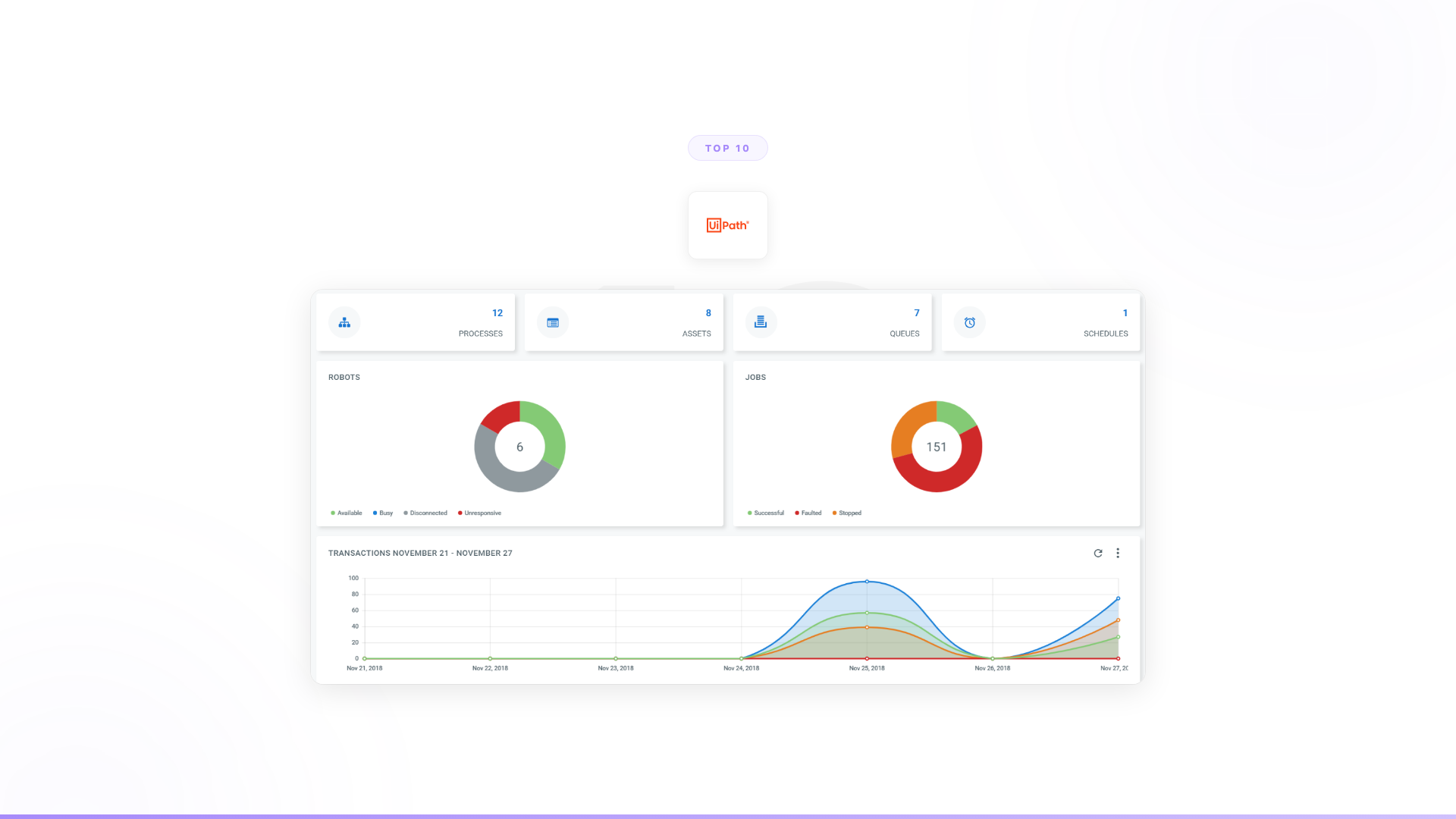
What it is: An enterprise AI agent platform paired with Forward Deployed Engineers who embed with your team. Nexus supports both real-time RAG (connecting agents to live data from CRMs, ERPs, and databases) and stored RAG (uploading documents from Confluence, Google Drive, SharePoint for vectorized knowledge). RAG is one capability within agents that complete entire business workflows.
Why it ranks first for enterprise RAG:
Every other tool on this list solves some version of "how do I get accurate answers from enterprise knowledge?" Nexus asks a different question: "What happens after you get the answer?"
For most enterprises, the bottleneck isn't retrieval. It's the workflow around it. A customer support agent doesn't just need to find the right troubleshooting article. It needs to pull the customer's account details, check their service tier, cross-reference the known issue database, determine if this qualifies for a service credit, apply it if so, and send a confirmation. A sales intelligence agent doesn't just need to find news about a prospect. It needs to synthesize signals across dozens of sources, score the opportunity, update the CRM, and route the insight to the right rep.
RAG handles step one. Nexus handles the entire process.
What it looks like in production:
- Orange Group (multi-billion euro telecom): Autonomous customer onboarding agents deployed across multiple European markets. 4-week deployment. 50% conversion improvement. 90% autonomous resolution. 100% team adoption.
- European telecom (13,000+ employees): A dozen agents deployed across support operations. 40% support volume freed across millions of interactions. Forward Deployed Engineers identified the highest-impact use cases and handled integration complexity.
What makes it different for enterprise:
- 4,000+ native integrations. RAG pulls from CRMs, ERPs, knowledge bases, communication tools, ticketing systems. Not just document stores.
- Business teams own it. No engineering dependency for day-to-day use.
- Forward Deployed Engineers. Real engineers embedded with your team who identify use cases, design agents, handle complexity, and manage organizational change.
- Enterprise governance from day one. SOC 2 Type II, ISO 27001, ISO 42001, GDPR. Full audit trails. Decision traceability. Role-based access.
- 100% POC-to-contract conversion. Every engagement starts with a 3-month POC tied to measurable outcomes.
Pricing: Per-agent, tied to value delivered.
Full Nexus vs Haystack comparison -->
2. Haystack
What it is: An open-source Python framework by deepset for building production-ready RAG pipelines. Haystack uses a pipeline-first architecture where you compose modular components (retrievers, readers, generators, rankers, document processors) into explicit, reproducible workflows. 24,000+ GitHub stars. Enterprise customers include Airbus and Siemens.
Why it's strong for enterprise RAG:
Haystack was built for retrieval from the ground up. deepset's roots are in NLP and enterprise search, and that heritage shows. The pipeline architecture gives developers explicit control over every step: document processing, embedding, retrieval, re-ranking, and generation. The component system validates compatibility before runtime, and pipeline serialization makes it straightforward to save and reproduce pipelines. For teams that need fine-grained control over their retrieval strategy — custom re-rankers, hybrid retrieval, multi-modal pipelines — Haystack provides that control cleanly.
The Haystack Enterprise Platform (formerly deepset AI Platform) adds managed infrastructure, a visual pipeline editor, governance, and access controls. For teams that want Haystack's pipeline architecture without managing all the infrastructure, it's a meaningful addition.
Where it falls short for enterprise:
Haystack excels at the retrieval layer. It doesn't address the workflow layer. For use cases that go beyond "find information and generate an answer" into "validate, decide, route, execute, and escalate across multiple systems," Haystack's pipeline architecture isn't designed for that scope. You'd build the retrieval step with Haystack and the remaining 80% of the workflow as custom engineering.
Haystack also assumes an engineering team. Pipeline design, component configuration, document store selection, embedding strategy, evaluation, and infrastructure management all require Python developers with retrieval expertise. The enterprise platform reduces infrastructure burden but doesn't change the fundamental model.
Pricing: Open-source (free). Enterprise Platform and Enterprise Starter: custom pricing.
Best for: AI engineering teams building retrieval-heavy applications where fine-grained control over the RAG pipeline is a priority.
3. LangChain
What it is: The most popular open-source framework for building LLM applications. 125,000+ GitHub stars. The ecosystem includes LangChain core, LCEL (expression language), LangGraph (graph-based agents), and LangSmith (observability). Supports RAG pipelines alongside agents, chains, memory, and tool use.
Why it's strong for enterprise RAG:
LangChain's breadth is its advantage. Where Haystack focuses on retrieval pipelines, LangChain covers RAG plus agents, tool use, conversation memory, and output parsing. For teams that need RAG as one capability within a broader AI application — an agent that retrieves documents AND calls APIs AND makes decisions — LangChain provides all the components under one umbrella. LangGraph adds sophisticated agent orchestration with state management, branching, and loops. LangSmith provides the observability layer for debugging and evaluation.
Where it falls short for enterprise:
Four interconnected products, each with its own learning curve, documentation, and pricing. Getting from a working RAG prototype to a production enterprise deployment requires significant engineering investment in security, compliance, integrations, monitoring, and maintenance. The framework's abstractions can be unpredictable: developers often find themselves fighting the framework rather than building their application, particularly as requirements get more complex.
Pricing: Open-source (free). LangSmith from $39/seat/month. LangGraph Platform charges per node execution.
Best for: Engineering teams building AI applications that need RAG alongside agent capabilities, who are comfortable managing a multi-product ecosystem.
Full Nexus vs LangChain comparison -->
4. LlamaIndex
What it is: An open-source framework focused on connecting LLMs to data. LlamaIndex provides sophisticated data connectors (LlamaHub), indexing strategies (knowledge graphs, hierarchical, vector), and query engines for building applications where LLMs reason over complex private data. LlamaCloud offers a managed RAG service.
Why it's strong for enterprise RAG:
For data-intensive retrieval, LlamaIndex goes deeper than most alternatives. It handles complex data structures (hierarchical documents, multi-modal content, structured + unstructured data), provides advanced indexing strategies (tree indexes, keyword tables, knowledge graphs alongside standard vector indexes), and supports sophisticated query planning. If your enterprise knowledge is messy, multi-layered, and distributed across diverse data sources, LlamaIndex's abstractions handle that complexity better than most frameworks.
Where it falls short for enterprise:
Like Haystack, LlamaIndex solves the retrieval problem deeply but not the workflow problem. It's the best tool for getting accurate answers from complex enterprise data. It doesn't help with what happens after you get the answer. For enterprise teams, the engineering requirements are significant: data pipeline design, index optimization, query engine configuration, and infrastructure management.
Pricing: Open-source (free). LlamaCloud has usage-based pricing.
Best for: Engineering teams whose primary challenge is building high-quality retrieval over complex, multi-format enterprise data.
5. Glean
What it is: Enterprise AI search and knowledge assistant. Connects to 100+ enterprise data sources and provides a unified search experience across all of them. Employees ask questions in natural language and get answers grounded in the company's knowledge.
Why it's strong for enterprise RAG:
Glean removes the engineering from enterprise search entirely. No pipelines to build. No infrastructure to manage. Connect your data sources (Confluence, Slack, Drive, SharePoint, Salesforce, Jira, and 100+ more), and employees get a search experience that spans all of them. The RAG is built in: answers are generated from your enterprise knowledge with citations. For the specific job of "help employees find information across fragmented tools," Glean does this without requiring any engineering.
Where it falls short for enterprise:
Glean answers questions. It doesn't complete workflows. If the bottleneck is "employees can't find information," Glean is excellent. If the bottleneck is "the process around that information requires validation, decisions, actions, and coordination across systems," Glean covers the search step but nothing beyond. It's also a per-user SaaS product, not a platform you build on. You can't customize the retrieval strategy or extend it into workflow automation.
Pricing: Per-user, custom enterprise pricing. Reportedly $15–25/user/month.
Best for: Enterprises where knowledge discovery is the primary bottleneck and the workflows around that knowledge are already functional.
Full Nexus vs Glean comparison -->
6. Vectara
What it is: RAG-as-a-service. Vectara provides a fully managed platform for document ingestion, embedding, indexing, retrieval, re-ranking, and generation. Upload documents, query with natural language, get answers with citations. No infrastructure management, no pipeline design.
Why it's strong for enterprise RAG:
Vectara solves the "I want RAG without the engineering" problem. The entire retrieval pipeline is abstracted: you upload documents and ask questions. Their proprietary re-ranking model (Boomerang) delivers strong retrieval accuracy. For teams that evaluated Haystack or LangChain and realized the pipeline engineering was more than they wanted, Vectara removes most of that work. It's particularly strong for document QA use cases: upload internal docs, let employees ask questions, get grounded answers.
Where it falls short for enterprise:
You trade control for convenience. Can't customize retrieval strategies to the same degree as Haystack or LlamaIndex. Can't build complex agent workflows on top. It's a RAG service, not an agent platform. For use cases beyond document question-answering, you'd need to build the rest of the application around Vectara's API.
Pricing: Free tier (50MB). Growth plans start at $150/month. Enterprise pricing is custom.
Best for: Teams that want production RAG quickly without managing infrastructure, and whose use case is primarily document question-answering.
7. Pinecone
What it is: A managed vector database purpose-built for AI applications. Pinecone provides fast, scalable vector similarity search that serves as the storage and retrieval backbone for RAG systems. Pinecone Assistant provides an integrated RAG experience.
Why it's strong for enterprise RAG:
Pinecone is battle-tested at scale. It handles billions of vectors with low-latency queries, and the managed service means no database administration. For enterprise RAG applications that need to scale — large document collections, high query volumes, multiple tenants — Pinecone provides infrastructure-level reliability that self-managed vector databases can struggle to match. The serverless option simplifies cost management.
Where it falls short for enterprise:
Pinecone is the storage layer, not the application. You still need to build the embedding pipeline, generation orchestration, application logic, and enterprise integrations. Pinecone Assistant moves toward a more complete RAG product, but it's focused on simple QA and doesn't address the broader enterprise workflow requirements.
Pricing: Free tier available. Standard from ~$70/month. Enterprise pricing is custom.
Best for: Engineering teams that need reliable, scalable vector search infrastructure as part of a larger RAG application.
8. Cohere
What it is: An enterprise AI model provider with dedicated embedding, re-ranking, and generation models. Cohere's Embed v3 and Rerank models are used in production RAG systems across industries. The platform includes a RAG toolkit for building enterprise knowledge applications.
Why it's strong for enterprise RAG:
Cohere's models are often the highest-performing components in a RAG stack. Their Rerank model is one of the best available, capable of dramatically improving retrieval accuracy when added to any pipeline. Embed v3 provides multi-lingual, multi-format embeddings with strong compression. For enterprises that need RAG in multiple languages or across diverse document types, Cohere's model capabilities are a genuine advantage. The enterprise focus means data privacy, SOC 2 compliance, and VPC deployment options.
Where it falls short for enterprise:
Cohere provides excellent building blocks, not a complete platform. You still need to architect the retrieval pipeline, build the application layer, manage integrations, and handle the workflow beyond retrieval. Cohere's RAG toolkit helps, but it's closer to a developer toolkit than an enterprise platform.
Pricing: Free trial. Production pricing based on API usage. Enterprise pricing is custom.
Best for: Teams that need enterprise-grade embedding and re-ranking models, either standalone or as components in a larger RAG system.
9. Elasticsearch
What it is: The established search platform, now with native vector search capabilities. Elasticsearch 8+ supports dense vector search (kNN), sparse vector search (ELSER), and hybrid retrieval combining traditional BM25 keyword search with semantic search. The Relevance Engine provides an integrated RAG experience.
Why it's strong for enterprise RAG:
If your organization already runs Elasticsearch (and many enterprises do), adding RAG capabilities doesn't require a new database. Elastic's hybrid search — combining keyword and semantic retrieval — is particularly valuable for enterprise content where exact matches and semantic understanding both matter. The operational maturity of the platform (monitoring, security, scaling, backups) is unmatched by newer vector databases. For large-scale enterprise deployments with strict operational requirements, that maturity matters.
Where it falls short for enterprise:
Adding RAG capabilities to Elasticsearch still requires building the embedding pipeline, generation orchestration, and application layer. While Elastic provides pieces of this, it's infrastructure and tooling rather than a complete solution. The learning curve for configuring vector search within Elasticsearch's broader ecosystem is also non-trivial.
Pricing: Open-source (self-managed). Elastic Cloud from $95/month. Enterprise licensing is custom.
Best for: Enterprises already using Elasticsearch that want to add semantic search and RAG capabilities without adopting a separate vector database.
10. Weaviate
What it is: An open-source, AI-native vector database with built-in vectorization, hybrid search, and generative modules. Weaviate handles embedding, storage, retrieval, and generation in a single platform. No separate embedding pipeline needed.
Why it's strong for enterprise RAG:
Weaviate bundles more RAG functionality into the database layer than any other vector database. Built-in vectorizers mean you can skip the embedding pipeline. Built-in generative modules mean simple QA applications can run without a separate generation service. Hybrid search (combining keyword and semantic) works out of the box. For teams that want to minimize the number of moving parts in their RAG stack, Weaviate handles more of the pipeline natively.
Where it falls short for enterprise:
For simple document QA, Weaviate's built-in modules may be sufficient. For anything that requires custom retrieval strategies, complex re-ranking, or workflows beyond question-answering, you're back to building orchestration around the database. The built-in modules are convenient but less configurable than dedicated frameworks.
Pricing: Open-source (self-hosted, free). Weaviate Cloud from $25/month. Enterprise pricing is custom.
Best for: Teams building AI-native search applications who want a single platform that handles vectorization, storage, search, and basic generation.
The enterprise RAG maturity curve
Most enterprises go through a predictable progression with RAG:
Stage 1: Using RAG for answers. "We need AI that answers questions from our documents." This is where most RAG projects start. Internal knowledge bases, documentation search, policy QA. Any framework on this list handles this well. Haystack, LlamaIndex, Vectara, and Glean are all strong choices depending on whether you want control (Haystack/LlamaIndex) or convenience (Vectara/Glean).
Stage 2: RAG for decisions. "The answers are good, but nobody's acting on them." The RAG system finds the right information. Employees read the answer. Then they still need to manually check two other systems, make a judgment call, update the CRM, and send a notification. The retrieval worked. The process didn't change.
Stage 3: RAG for workflow automation. "We don't just need search. We need AI that completes the work." This is where the category shift happens. Retrieval is one step. The enterprise needs agents that take the retrieved information and do something with it: validate, decide, route, execute, escalate, update, notify. End to end. Autonomously. With governance.
What triggers the move from Stage 2 to Stage 3? Usually one of three things: the team realizes that manually acting on AI-surfaced information is itself becoming the bottleneck; the use case spans multiple systems and hand-offs; or the volume of decisions exceeds what people can review in real time. At that point, search and retrieval are solved — orchestration and execution aren't.
Most frameworks on this list serve Stages 1 and 2 well. Nexus is built for Stage 3.
Orange's agent doesn't just pull product information during onboarding. It collects customer data, validates against CRM and billing systems, checks compatibility, routes edge cases, escalates with context, updates systems, and sends confirmations. 50% conversion improvement. 4-week deployment.
The question for your team isn't which RAG framework is best. It's which stage you're at, and where you need to be.
Frequently asked questions
What is RAG (Retrieval-Augmented Generation)?
RAG is an AI architecture pattern where a model retrieves relevant documents or data from external sources before generating a response. This grounds the output in real, up-to-date information rather than relying solely on what the model learned during training. The approach was formally introduced in Lewis et al.'s 2020 NeurIPS paper and has since become the standard architecture for enterprise knowledge AI. In practice, RAG systems work in two steps: first, retrieve the most relevant context from a vector database or search index; second, feed that context to a language model to generate an accurate, cited answer.
What is the difference between RAG and fine-tuning?
Fine-tuning modifies the model's weights to incorporate your domain knowledge permanently. RAG retrieves fresh information at query time without changing the model. For most enterprise applications, RAG is the right choice because enterprise knowledge changes frequently (pricing, policies, product catalogs, customer records) and because RAG produces auditable, citation-backed answers. Fine-tuning is better suited to changing model behavior or style — not to keeping knowledge current. Many production systems use both: fine-tuning for domain terminology and RAG for dynamic knowledge retrieval.
What is the difference between RAG and AI agents?
RAG answers the question "how does the AI get accurate information?" — it's a retrieval architecture. AI agents answer the question "what does the AI do with that information?" — they execute actions across systems. A RAG-only system returns grounded answers. An agent system takes those answers and acts on them: updates records, triggers workflows, routes tasks, escalates exceptions. Enterprise use cases typically need both: RAG for retrieval accuracy and agents for downstream execution.
Which enterprise RAG framework is easiest to deploy?
It depends on your use case and team. For teams that want RAG without any infrastructure management, Vectara and Glean are the fastest paths to production — upload documents, start querying, no pipeline engineering required. For teams with engineering capacity that want control over their retrieval strategy, Haystack and LlamaIndex offer more flexibility. For enterprises that need RAG as part of a complete workflow automation capability, Nexus bundles retrieval with execution and comes with Forward Deployed Engineers who handle the deployment complexity.
What are the enterprise compliance requirements for RAG systems?
Enterprise RAG deployments typically need: SOC 2 Type II certification for security controls; GDPR compliance for data residency and processing (particularly relevant for European enterprises); role-based access controls to ensure retrieved data respects existing permissions; full audit trails for every retrieval and generation decision; and data isolation between tenants in multi-tenant deployments. Some regulated industries (financial services, healthcare) also require additional controls around data retention and explainability. Of the platforms in this guide, Nexus, Cohere, and Glean publish the most complete compliance documentation. Haystack and LlamaIndex are frameworks — compliance responsibility sits with the team building on top.
Worth exploring?
If your team is building enterprise RAG and you're starting to see the gap between retrieval and workflow completion, it might be worth a conversation about what Stage 3 looks like.
Every Nexus engagement starts with a 3-month proof of concept tied to measurable business outcomes. Forward Deployed Engineers embed with your team from day one. You see the results before committing. You can exit anytime.
100% of clients who started a POC converted to an annual contract. Every one.
See the full Nexus vs Haystack comparison -->
Related reading
- Top 10 Haystack Alternatives for AI Search and RAG
- Haystack vs LangChain: AI Frameworks Compared
- How to Build a RAG Pipeline for Enterprise
- Nexus vs Haystack: full comparison
- Nexus vs LangChain: full comparison
- Nexus vs Glean: search assistant vs autonomous agents
- Top 10 LangChain Alternatives for Building AI Agents
The RAG methodology was first formally described in: Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." NeurIPS 2020. Market size data sourced from ResearchAndMarkets 2025 RAG Industry Report. Enterprise adoption figures from Grand View Research Retrieval Augmented Generation Market Report.