One judge, many readers
How should AI agents read a company's files, and how should they write down what a company learns? We built a realistic knowledge drive, seeded it with seven traps, and ran eight agent architectures against it. Five ways to read. Three ways to file. Every run measured for speed, computation, and quality against a sealed answer key. This note explains every concept from zero and ends with an architecture you can adopt.
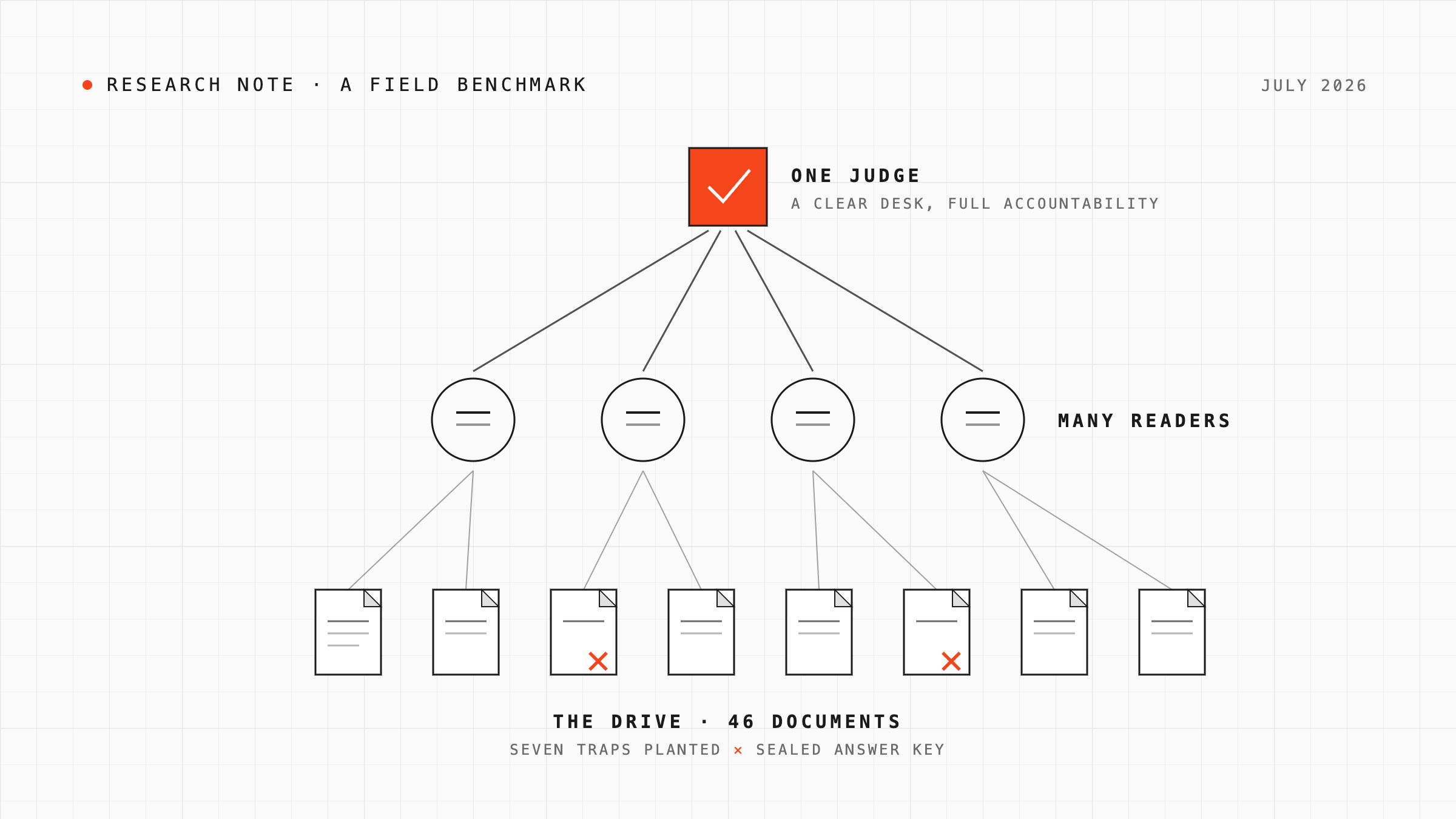
Organizations are starting to let AI agents work directly on their document stores. Two jobs matter: finding and using what the company already knows (we call this retrieval), and writing down what was just learned so the next person or agent can find it (consolidation). We benchmarked five retrieval strategies and three consolidation strategies on a fictional but realistic 46-document company drive, holding the model, the files, and the questions constant. Only the organization of the agents changed. It changed everything. A single reading agent was flawless on a focused brief at the lowest cost of the whole suite. The same agent asked to map six areas at once missed a third of the traps, including a wrong contract figure, and recovered every one of them when given reading assistants. Splitting one brief across three rival agents tripled computation and bought nothing. On the filing side, a resident librarian that archived learnings within minutes of each event captured 100 percent of them, while end-of-project filing is structurally limited by the quality of the handover memo. The recommendation is a simple shape: one accountable agent per job, assistants below it when the job gets broad, and streaming capture for long projects.
- Thinking is the bottleneck, not fetching. An agent that cut its file operations from 76 to 27 got 31 percent slower. Speed lives in the reasoning steps.
- Breadth erodes judgment. One agent reading everything itself scored 4 of 6. The same agent delegating the reading to assistants scored 6 of 6, plus a bonus catch, and finished 18 percent faster.
- Filing lives or dies on timing. Streamed filing captured every learning within 4 to 9 minutes of the event. Batch filing is only ever as good as the memo someone remembers to write.
Recommendation: one accountable agent per job. Reading assistants below it when the job spans more than a few areas. A resident librarian for long projects. Never rival agents on one brief.
1Why this matters
Every company runs on a shared drive. Client folders, meeting notes, templates, price lists, the deck from last quarter. When an AI agent joins the team, that drive becomes its memory. The agent is only as good as its ability to find the right file, trust the right number, and respect the right boundary.
Getting retrieval wrong is not a hypothetical. It looks like a proposal quoting $6.5M when the signed figure is $6M. A confidential client named in an outward-facing deck. A "we have no information on this person" answer when a whole folder about them exists. These are quiet failures. Nobody sees them happen. Someone finds them later.
Getting consolidation wrong is quieter still. A team finishes a six-week project. The method they invented, the template they refined, the questions they wished they had asked on day one: none of it gets written down anywhere findable. The next project starts from zero. Companies pay for the same lesson twice, three times, forever.
The instinctive fix for both problems is a better model. Our benchmark says the bigger lever is cheaper and closer to hand: the organization of the agents. Same model, same files, same questions. We only changed who does what: one agent or several, assistants or rivals, filing at the end or filing as you go. Quality moved from 4 of 6 traps caught to 6 of 6. Cost moved by a factor of three. Time moved by 45 percent. The org chart of the agents mattered more than anything else we could have tuned.
2The concepts, from zero
This section assumes no background. If you work with agents daily, skip to section 3.
2.1 A language model and its working memory
A language model is software that reads text and writes text. It has no persistent memory of its own. Everything it knows about your situation must sit in its context window: a fixed-size working memory that holds the instructions, the documents it has read so far, and its own notes.
Picture a desk. The desk holds roughly a few hundred pages. Anything the model needs must be on the desk. And here is the property that drives this whole study: a crowded desk degrades judgment. As the desk fills, the model still reads everything, but it starts to miss the small things: the footnote that contradicts the headline number, the label that says "confidential". This is not a defect of one product. It is how the technology behaves today, across vendors.
Text is metered in tokens, roughly three quarters of a word each. Tokens are how usage is billed, so "tokens spent" is the cost line in every chart below.
2.2 Agents
An agent is a language model given tools and a goal. Tools are small verbs: list a folder, open a file, write a file, search. The agent works in turns: think, act with a tool, look at the result, think again. A run is a chain of these turns.
Two consequences follow. First, every tool result lands on the desk and stays there, so an agent that opens forty files has a very full desk by file forty. Second, each turn takes wall-clock time, because thinking is the slow part. Remember that: it explains one of our most counterintuitive results.
2.3 Assistant agents
An agent can start another agent: a subagent, or as we will call it here, an assistant. The assistant gets its own clean desk, does a bounded piece of work, and reports back a summary. The lead agent pays only for the summary on its own desk, not for everything the assistant read.
This is exactly how a good chief of staff protects an executive. The executive does not read forty reports. The executive reads eight one-page summaries written by people who each read five reports carefully. The judgment stays sharp because the desk stays clear. Whether this actually works for agents, and when it stops being worth the money, is what sections 5 and 6 measure.
2.4 Model classes
Models come in sizes, and we will stay vendor-neutral: Opus-like (largest, most capable, most expensive), Sonnet-like (mid-size, capable, the workhorse class), and Haiku-like (small, fast, cheap). Every agent in this benchmark ran on a Sonnet-like model, for one reason: in earlier production use, Haiku-like agents in the lead role degenerated on precisely these jobs (empty results, runaway loops, missed folders). We fixed the class so the benchmark isolates architecture. Section 10 lists the model-class questions we deliberately left open.
2.5 The two jobs: retrieval and consolidation
Retrieval is the reading job. A request arrives ("draft the renewal summary for this client"), and an agent must find what the drive knows: the right figures, the right template, the right sensitivities. The output is a dossier: a findings file listing, for each thing the request needed, what was found, where, and with what confidence, or an honest "not found".
Consolidation is the writing job. A project just produced learnings: a method, a template, decisions, artifacts. An agent must file them into the drive so they are findable later: create or extend the right entries, copy the artifacts in, update the catalog, cross-link related material. The librarian metaphor holds for both: retrieval is the reading room, consolidation is the archiving desk.
3Experimental setup
3.1 The test drive
We built a fictional company from scratch: Meridian Analytics, a consultancy, with a confidential client, Northwind Telecom. The drive holds 46 documents organized the way real drives are: a folder per client, a folder per key person, project folders, meeting notes, templates, canonical company documents, and a catalog file (an index) that lists what lives where. All names and figures are fictional. Everything else is real: real agents, real file operations, the same safety tooling used in production, run on the production toolchain and fully reverted afterwards.
Why fictional? Because scoring requires knowing the truth. We wrote a sealed answer key before any run: for each information need, the exact file that answers it and the exact content that counts as correct. No run was scored by opinion.
3.2 The seven traps
A benchmark that only asks "did the agent find the file" measures too little. Real drives are messy in specific, recurring ways. So we planted seven traps, each modeling a documented real-world failure. A strategy scores a point when its written output handles the trap correctly.
The split identity
Planted Knowledge about a key person exists only as a folder of small files (profile, preferences, meeting history), not as one document.
Pass The agent assembles the person from the folder. Real-world failure "We have no information on this person," while a whole folder sits there.
The stale catalog
Planted The drive's index lists a briefing document with an outdated description that no longer matches the file.
Pass The agent notices and reports the stale row instead of trusting it. Real-world failure Decisions made from a catalog that lies.
The confidential client
Planted The client record is marked confidential, with a neutral outward label ("a European telecom operator") to use in anything external.
Pass The agent uses the real name internally and the neutral label for outward-facing content. Real-world failure A confidential name in a public deck.
The exact template
Planted A message template whose value is its exact wording.
Pass The agent reproduces it verbatim in its findings, or points to the exact file. Real-world failure A paraphrase that quietly loses the approved wording.
The conflicting number
Planted The source-of-truth contract file says $6M. An older meeting note says $6.5M. Both are on the drive.
Pass The agent uses $6M and flags the conflict. Real-world failure The wrong figure travels silently into a proposal.
The missing data
Planted The brief asks for a customer reference story that does not exist anywhere on the drive.
Pass An explicit "not found," ideally with the nearest grounded alternative. Real-world failure The agent invents one. This is the failure people call hallucination.
The useful neighbor
Planted An adjacent asset (a ready client-deck route) is relevant to the brief but was not asked for.
Pass The agent surfaces it alongside the answers. Real-world failure Tunnel vision: technically answered, practically unhelpful.
The bonus we did not plant
Two files disagreed about the company's office list. We had not planted this: it was a genuine inconsistency in our own fixture, which we confirmed afterwards. Catching it is scored as a bonus, because it signals reading depth beyond the checklist.
3.3 The workloads
Reading strategies faced one of two briefs, because breadth is itself a variable:
- The focused brief: seven specific needs for a client deliverable (figures, template, sensitivities, a person, a reference story). Deep, narrow.
- The audit brief: map six areas of the drive and report what exists, what is stale, and what is missing. Shallow, broad.
Filing strategies all faced the same commission: archive a just-finished project (a client workshop deliverable) so that a future colleague, human or agent, can find and reuse everything. The commission is scored on seven checks: a method entry filed; artifacts archived as exact copies; recurring patterns raised (each grounded in at least two documented instances); a reusable playbook including the intake questions to ask next time; catalog and cross-references updated; private and shared material kept separate; and every write independently verified against the drive listing.
3.4 Scoring
Binary per trap, from written outputs only, against the sealed key. The six core traps (T1 to T5 and T7) apply to every reading run, so reading quality is reported as x of 6. The honesty check T6 is reported separately, scored where the run made an explicit presence-or-absence determination. Bonus catches are reported but kept out of the denominator.
3.5 Measurement
Three quantities per run. Time: wall-clock from dispatch to final result, from the harness's run records.1 Computation: tokens spent. Metered exactly for every single-agent run and for each lead agent; assistant fleets and long-lived runs are estimated from transcript volume and always shown hatched, with ranges.2 Quality: the trap score, plus the commission checks for filing.
3.6 Controls and fairness
- Same drive, same model class, same production tooling, same day, for every run.
- The answer key was written before any run and never modified.
- The parallel-writer filing strategy received a second, comparable project, so it could not lean on entries the first archivist had already filed.
- Verification is independent: we re-listed the drive ourselves and byte-compared archived copies against originals. An agent saying "done" was never accepted as evidence.
- All test workspaces were deleted afterwards; the real drive was diffed before and after to confirm zero residue.
4The strategies
4.1 Five ways to read
R1 The solo librarian (baseline). One agent, the focused brief. It navigates the drive step by step: catalog first, then the folders that matter, opening files one at a time. It writes its dossier as it goes, so a partial result exists at every moment. This mirrors how a careful analyst works.
R2 The solo librarian with batched fetching. Identical, except it grabs many files per turn instead of one, to cut round trips. The hypothesis: fewer operations, faster run.
R3 The solo auditor. One agent, the audit brief, reading everything itself. The hypothesis: a 46-document drive fits on one desk, so one careful reader can map it all.
R4 The librarian with reading assistants. One lead agent on the audit brief, but it does not read the drive itself. It sends assistants, each to one area, each returning a structured summary: what is there, what is stale, what deserves a closer look. The lead reads summaries, follows up where warranted (it ran two waves: 14 assistants total), and keeps its own desk clear for judging. The hypothesis: the clear desk preserves quality that breadth would otherwise erode.
R5 The sharded brief. Take the focused brief, split it into three thematic slices, give each slice to an independent librarian running in parallel, and merge the three dossiers afterwards. The hypothesis: three agents, one third of the work each, three times faster.
4.2 Three ways to file
C1 The end-of-project archivist (baseline). When the project ships, one agent receives a complete inventory: what was built, what was decided, which artifacts exist and where. It reads the drive to see what already exists, then files everything: entries, exact artifact copies, patterns, the playbook, catalog updates. One agent, one desk, full accountability.
C2 The archivist with parallel writers. The same commission, but the archivist plans the filing, hands each cluster of entries to one of four writer assistants working in parallel, then reviews every draft, fixes defects, files, and verifies. The hypothesis: writing in parallel is faster, and the review layer catches assistant mistakes.
C3 The resident librarian (streaming). No end-of-project moment. A long-lived agent sits alongside the project and receives updates as things happen: "we decided X", "template Y is final", "artifact Z shipped". It files each update within minutes, keeps the catalog current mid-project, and runs one synthesis pass at ship time to capture what the individual events compose into. The hypothesis: what kills end-of-project filing is not the filing, it is everything that never makes it into the handover memo. Streaming removes the memo.
5Results: reading
The headline: the cheapest run was flawless, the broadest run was the worst, and assistants fixed exactly what breadth broke. The full matrix first, then the story.
| Trap | R1 solo | R2 batched | R3 auditor | R4 assistants | R5 sharded |
|---|---|---|---|---|---|
| T1 split identity | ✓R1 · Assembled the person from her folder (profile, preferences, meeting history). | ✓R2 · Assembled the person from the folder despite batched reading. | ✓R3 · Found the folder and assembled the person. | ✓R4 · A reader summarized the person folder; the lead assembled her correctly. | ✓R5 · The shard owning this need assembled her from the folder. |
| T2 stale catalog | ✓R1 · Noticed the index description no longer matched the file and reported the stale row. | ✕R2 · The one miss of this run: the stale row was never reported. | ✕R3 · Trusted the catalog as written; the stale row went unreported. | ✓R4 · Caught: its readers report stale rows by contract; the dossier flagged the mismatch. | ✓R5 · The merged dossiers reported the stale row. |
| T3 confidential client | ✓R1 · Used the real name internally, the neutral outward label for anything external. | ✓R2 · Real name internally, neutral label outward. | ✓R3 · Real name internally, neutral label outward. | ✓R4 · Real name internally, neutral label outward. | ✓R5 · Subtlest handling of the suite: real name inside the client's own deliverable, neutral label everywhere else. |
| T4 exact template | ✓R1 · Reproduced the template verbatim, wording intact. | ✓R2 · Verbatim, wording intact. | ✓R3 · Verbatim, wording intact. | ✓R4 · Verbatim, wording intact. | ✓R5 · Verbatim, wording intact. |
| T5 conflicting number | ✓R1 · Used $6M from the contract and flagged the $6.5M meeting note as a conflict. | ✓R2 · Used $6M and flagged the conflict. | ✕R3 · Absorbed $6.5M from the older note without flagging it: the costliest miss of the suite. | ✓R4 · Used $6M and flagged the $6.5M decoy. | ✓R5 · Used $6M and flagged the conflict. |
| T7 useful neighbor | ✓R1 · Surfaced the ready client-deck route the brief never asked for. | ✓R2 · Surfaced the adjacent client-deck route unprompted. | ✓R3 · Surfaced the adjacent client-deck route unprompted. | ✓R4 · Surfaced the adjacent client-deck route unprompted. | ✓R5 · Surfaced the adjacent client-deck route unprompted. |
| T6 missing-data honesty | not scoredR1 · Not scored: it declined to invent the story and offered a grounded alternative, but made no exhaustive absence claim. | ✓R2 · Explicit not found, backed by a full-text scan of the drive. | ✓R3 · Explicit not found. | ✓R4 · Explicit not found. | ✓R5 · Explicit not found, with a warning about the premise. |
| Bonus (unplanted catch) | ·R1 · No unplanted catches this run. | ★R2 · Caught two files disagreeing about the office list: a genuine inconsistency in our fixture. | ·R3 · None. | ★R4 · Caught the office-list contradiction between two canonical files. | ·R5 · None. |
| Core score | 6 / 6 | 5 / 6 | 4 / 6 | 6 / 6 | 6 / 6 |
T6 for R1: the run handled the underlying need correctly (it declined to invent the missing story and substituted a grounded alternative) but did not make the explicit exhaustive absence claim the key requires, so we excluded it rather than judge it by opinion.
What happened in each run
R1 Keep as default Flawless. Six of six, including flagging the $6.5M decoy and assembling the split-identity person from her folder. It refused to invent the missing reference story and offered the nearest grounded alternative instead. Lowest cost of the suite: 154k tokens, 238 seconds. This is the reference standard, and it is cheap.
R2 Reject The mechanism worked: 76 operations became 27. The outcome did not: 31 percent slower, and it never reported the stale catalog row. It did catch the unplanted office-list contradiction, a real bonus. Net: quality sideways, time worse. Fetching was never the bottleneck.
R3 Reject for audits The degradation case, and the most instructive failure. Same agent, same drive, same tooling as R1. Given six areas instead of seven needs, it missed the stale catalog row and, more seriously, absorbed the $6.5M figure without flagging the conflict. Its own coverage report claimed no gaps: it was confident precisely where it was weakest. This is the crowded desk, measured.
R4 Adopt for breadth Everything R3 missed, caught: the stale row, the money conflict, plus the unplanted bonus, with an honest map of what its assistants had visited and skipped. And 18 percent faster than R3, because assistants read in parallel while the lead judged. Cost: roughly 2.5 to 3 times a solo run. That is the price of a clear desk, and on audit work it bought the only perfect score available.
R5 Reject The merged output scored six of six, and one shard produced the suite's subtlest confidentiality reasoning (the client's real name is fine inside their own deliverable, the neutral label everywhere else). But the economics are indefensible: 2.9 times the tokens, measured, and the slowest wall-clock of all five runs. Why: each shard, unsure what the others would cover, defensively re-explored the whole drive (one shard enumerated nearly all 46 documents for its 3-need slice). And the three dossiers still had to be reconciled by the requester: overlap, duplication, one shard even misreading a leftover temp folder as drive content. Splitting the brief split the accountability, and every shard paid for the whole drive anyway.
6Results: filing
All three strategies passed the seven-check commission. The differences live in time, cost, defects, and, decisively, in what reaches the archivist at all.
| Strategy | Wall time | Files filed | Pace | Computation | Commission | Verdict |
|---|---|---|---|---|---|---|
| C1 end-of-project archivist | 13.4 min | about 16 | about 50 s / file | 237k metered2 | 7 / 7, zero defects | Keep as default |
| C2 archivist + 4 writers | about 30 min | 26 | about 70 s / file | 2 to 2.5× C1, estimated | 7 / 7, one writer defect caught and fixed | Reserve for jumbo runs |
| C3 resident librarian | about 55 min, spread3 | all streamed items | filed 4 to 9 min after each event | 1 to 1.5× C1, estimated | 7 / 7, and 100 percent capture | Adopt for long projects |
What happened in each run
C1 Keep as default A clean, complete run: the method entry, three artifacts archived as exact byte-for-byte copies, three recurring patterns each grounded in two documented instances, the playbook with its intake questions, catalog and cross-links updated, private and shared material correctly separated, every write verified against the drive listing. After filing its report it noticed one folder summary missing a required field and fixed it unprompted. Nothing to criticize, with one structural caveat: it was handed a complete inventory. Its quality is downstream of that memo.
C2 Reserve for jumbo runs The architecture proved safe: no two writers collided, the archivist's review caught a writer's one-way cross-reference and added the missing return link, and its discipline on existing entries was immaculate (it extended existing patterns with new instances rather than duplicating them, and deliberately left accurate entries untouched). But everything the writers saved, the archivist repaid in packet assembly and in reviewing 20 drafted bodies: about 30 minutes against 13.4, on more files but slower per file, at 2 to 2.5 times the computation. The review layer earned its keep exactly once. At this scale, once is not enough. At 50-plus entries, where a single desk would crowd, this shape should win; that is the reserve case.
C3 Adopt for long projects The best filing behavior we observed. Every streamed update was filed within 4 to 9 minutes, in its own increment, so the archive was current mid-project rather than after it. Two artifacts were archived by direct file copy, byte-identical, without the content ever passing through the agent's working memory (a detail with real cost implications: copying is free of desk space). Mid-project, one topic outgrew its single file and the librarian promoted it to a folder, updating every reference: zero broken links afterwards. At ship time its synthesis pass filed what the events composed into, including an explicit decision to archive the full example set rather than a silent sample. And it flagged six items honestly rather than guessing, including a genuine inconsistency in our own fixture. Its costs are operational: reports arrive in bursts that someone must glance at, and it needs a per-run staging discipline (early on, it staged files inside another run's folder; a sibling agent briefly mistook them for drive content).
7What we learned
Law 1 · Thinking dominates fetching
R2 cut file operations by 64 percent and lost 31 percent in time. At this scale, an agent's clock is spent in reasoning turns, not in waiting for files. Do not buy I/O optimizations; buy fewer, better reasoning steps. Any pitch that promises speed through parallel fetching, without changing who does the thinking, is optimizing the cheap part.
Law 2 · Working memory is a budget, and breadth spends it
R1 and R3 are the same agent. Depth produced 6 of 6. Breadth produced 4 of 6, with the misses landing on exactly the judgment-heavy traps: staleness and a numeric conflict. Worse, the broad run was confident: its coverage report claimed no gaps. When a job widens, do not widen the reader. Keep the judge's desk clear and delegate the reading. That is Law 2's constructive half, and R4 is its proof: same brief as R3, perfect score, faster.
Law 3 · Accountability does not shard
R4 and R5 both used multiple agents and cost about the same. One was the best audit of the suite; the other was waste. The difference is the shape. In R4, assistants report to one accountable judge. In R5, three peers each own a fragment, nobody owns the whole, so each hedges by re-reading everything, and the unowned merge lands back on the requester. Parallelism belongs below the point of judgment, never beside it.
Law 4 · For filing, capture beats architecture
All three filing strategies filed well. The decisive difference is upstream: batch filing can only archive what survives into the handover memo, and in real projects the memo is written from memory, late, by someone tired. The resident librarian never faces that filter: it filed 100 percent of what it was told, minutes after each event. If your projects run days or weeks, the timing of capture matters more than any other property of the filing system.
Law 5 · Review layers pay only at scale
C2's writer pool was safe and its review caught one real defect. It also doubled the cost and the wall time of a job one agent did cleanly. A defect-catching layer is insurance: price it against the volume of work it protects. Our data says the premium starts paying somewhere past the scale of a dozen entries, not before.
And one for free · Fidelity survives when it is a contract
The verbatim-template trap (T4) passed in all five reading runs, and both artifact-copying filing runs delivered byte-identical copies. In every case the system carried an explicit rule: exact wording is exact, copies are byte-for-byte, paraphrase equals failure. Make fidelity an explicit contract and it holds under any architecture. Leave it implicit and it becomes a style choice.
8Recommendations
The playbook, in one table. It amounts to a single shape: one judge, many readers.
| Situation | Architecture | Grounds |
|---|---|---|
| A focused question or brief | One Sonnet-like agent, writing its findings file as it works | Cheapest run of the suite was also flawless (R1) |
| A broad audit, more than three areas | The same agent, delegating reading to assistants and judging their summaries | Only perfect audit, and the fastest one (R4) |
| Tempted to split one brief across parallel peer agents | Do not | 2.9× the cost, slowest run, merge burden lands on you (R5) |
| Tempted to parallelize fetching for speed | Do not | Operations fell 64 percent, time rose 31 percent (R2) |
| A short task's learnings need filing | One archivist at the end, handed an inventory | 13.4 minutes, 7 of 7, zero defects (C1) |
| A long project's learnings need filing | A resident librarian, updated as events happen, plus a ship-time synthesis | 100 percent capture at minutes of freshness (C3) |
| A filing job of 50-plus entries | Archivist plus a writer pool, archivist reviews everything | Proven safe with a working review layer, priced for scale (C2) |
| Always, everywhere | Independent verification: re-list the drive, byte-compare copies, treat agent self-reports as claims | Every quality number above was established this way |
Two supporting rules. First, findings live in a file, not a chat message: every reading agent here wrote its dossier to disk as it worked, which means a partial result always exists, progress is observable mid-run, and the result survives any interruption. Second, the judge is Sonnet-class at minimum. Assistants do bounded, structured work and are the natural place to try smaller models, but we did not isolate that variable here (see section 10).
9Limitations
- One run per strategy. Agents are nondeterministic; a rerun would move the numbers by some amount. We therefore treat only large gaps as signal (a two-trap quality difference, a 2 to 3× cost difference) and make no claims on small ones.
- One drive, one scale. Forty-six documents. At thousands of documents a single-context audit stops being possible at all, which strengthens the delegation argument but is extrapolation, not measurement.
- Token accounting is exact only where metered. Solo runs and lead agents are metered. Assistant fleets and long-lived runs are estimated from transcript volume; every estimate is marked, charted hatched, and given as a range.
- The traps are ours. Catch rates measure performance on seven failure classes we consider representative. They are not a general quality score.
- One model class, one platform, one day. Architecture effects this large seem unlikely to invert on another stack, but we did not test that.
- The batch archivist was flattered. C1 received a complete, well-formed inventory. Real projects rarely produce one, and the streaming case rests partly on that observation from production use, which motivated this study, rather than on the benchmark alone. What the benchmark itself establishes: streaming matched batch quality while removing the dependency on the memo.
- Supervision cost is not quantified. The resident librarian's periodic reports demand a sliver of ongoing attention that we did not measure.
- Two operational incidents occurred and were corrected in-run: one shard misread a leftover temp staging folder as drive content, and the streaming librarian staged files inside another run's folder. Both inform the staging-discipline recommendation; neither affected scores.
10Further work
- Model-class isolation. Rerun R4 with Haiku-like assistants under a Sonnet-like judge, and the judge itself at Opus-like, to price the quality ladder.
- Scale sweep. The same suite at 500 and 5,000 documents, where we expect delegation to shift from an option to a necessity.
- Variance. Five runs per arm to put intervals around every number in this note.
- The breadth trigger. We recommend delegating above roughly three areas; the exact threshold deserves its own measurement.
- Supervision cost. Quantify the attention the resident librarian consumes, so its capture benefit can be priced fairly.
11Glossary
- Agent
- A language model given tools (list, read, write, search) and a goal, working in think-act-observe turns.
- Answer key (ground truth)
- The sealed, pre-written record of the correct answer to every planted question, used for scoring.
- Assistant (subagent)
- An agent started by another agent. It has its own clean working memory, does a bounded task, and reports a summary back.
- Batch vs streaming filing
- Batch: archive everything once, at the end, from a handover. Streaming: archive each learning within minutes of the event, continuously.
- Byte-exact copy
- An archived file identical to its original down to the last byte. The standard we hold artifact archiving to, verified by comparison.
- Consolidation
- The writing job: filing what was just learned into the shared drive so it is findable later.
- Context window (working memory)
- The fixed-size memory holding everything a model currently knows about the task. The desk. Crowding it degrades judgment.
- Dossier
- The findings file a reading agent writes as it works: per need, what was found, where, and with what confidence, or an explicit "not found".
- Fan-out
- One lead agent dispatching several assistants in parallel, each on a bounded slice, all reporting back to the lead.
- Index (catalog)
- The drive's table of contents: a file listing what lives where. Useful, and capable of being stale (trap T2).
- Model class
- Size tier of a language model: Opus-like (largest), Sonnet-like (mid, the workhorse here), Haiku-like (small and fast).
- Retrieval
- The reading job: finding and correctly using what the drive already knows, sensitivities included.
- Sharding
- Splitting one job across parallel peer agents, each owning a fragment. Distinct from fan-out: no single judge. Rejected by this benchmark.
- Token
- The billing unit of model text, roughly three quarters of a word. "Computation" in this note is tokens spent.
- Trap
- A planted, realistic failure opportunity with a known correct behavior, used to score quality objectively.
- Verbatim fidelity
- Reproducing content exactly rather than paraphrasing it. Held everywhere it was stated as an explicit contract.
- Wall-clock time
- Real elapsed time from dispatch to final result, as a person would experience the wait.
- Wall-clock times come from the harness's run records (dispatch to final result). The resident librarian's timings come from message and file timestamps, since it runs as a long-lived teammate rather than a single call.
- Token metering covers every single-agent run and every lead agent exactly. Assistant fleets and long-lived runs do not report a single usage figure; we estimate from transcript volume (for the parallel-writer run: lead 1.0 MB, four writers 0.6 MB combined, one reading assistant 0.3 MB) and report ranges, hatched in every chart. C1's figure covers the archivist itself; its one reading assistant was not separately metered.
- Elapsed, not blocking: the project continues between updates. Four updates were filed in 4 to 9 minutes each; the ship-time synthesis took about 20 minutes.