How to Evaluate Open-Source AI Agent Frameworks (2025 Enterprise Guide)
Open-source agent frameworks are free to download but not free to deploy. Use these 8 criteria — security, governance, integrations, TCO, and more — to evaluate any open-source AI agent framework for enterprise production.
Evaluating open-source AI agent frameworks for enterprise production requires more than a GitHub star count or a quick prototype. The core criteria are security posture, governance and compliance, integration depth, who can build agents, consistency at scale, time to production value, total cost of ownership, and support model. The framework itself — agent orchestration, tool use, memory — typically covers about 20% of what production requires. The other 80% falls on your team.
That's not a reason to avoid open-source. Frameworks like AutoGen, CrewAI, LangChain, and LangGraph offer genuine advantages: flexibility, transparency, no vendor lock-in, and strong engineering communities. But "free to download" and "ready for enterprise production" are not the same statement. This guide walks through eight evaluation criteria with honest trade-offs, so your team asks the right questions before committing engineering resources.
The 8 evaluation criteria
1. Security posture
What to evaluate: Is security built into the architecture, or is it something your team adds?
Open-source agent frameworks vary widely on security defaults. AutoGen includes sandboxed code execution in Docker containers. LangChain and CrewAI do not sandbox execution by default, leaving tool access controls to the implementation team.
Independent security research underscores how significant these gaps are. A 2024 peer-reviewed penetration testing study published on arXiv (Penetration Testing of Agentic AI: A Comparative Security Analysis Across Models and Frameworks) tested AutoGen and CrewAI across 13 attack scenarios. Overall, more than half of malicious prompts succeeded despite enterprise-grade safety mechanisms (41.5% refusal rate across all configurations). CrewAI on GPT-4o was convinced by a local file to exfiltrate private user data in 65% of attempts. The researchers also found that Magentic-One (an AutoGen-based orchestrator) executed arbitrary malicious code 97% of the time when interacting with a malicious local file.
The OWASP Top 10 for LLM Applications (Version 1.0, February 2025) identifies prompt injection as the top risk for agentic deployments — and notes that most vulnerabilities stem from insecure design patterns (poorly scoped prompts, missing input validation, overly permissive tool access) rather than framework-specific bugs. This means the security burden largely falls on whoever configures and deploys the framework.
Questions to ask:
- Does the framework include sandboxed execution environments?
- What CVEs have been documented, and how quickly were they patched?
- Does the framework manage secrets and API keys securely?
- What happens when an agent has access to shell commands, email, or databases? Who controls the blast radius?
- Has the framework undergone third-party security audits?
The enterprise gap: Even the most security-conscious open-source framework does not provide SOC 2 Type II, ISO 27001, or GDPR certification. These certifications require organizational processes, audit infrastructure, and continuous compliance monitoring that no framework ships with. If your compliance team requires these certifications — and in regulated industries, they will — you are building that layer yourself or selecting a certified platform.
Security comparison:
| Framework | Sandboxed execution | Known security research findings | Third-party audit | Enterprise certifications |
|---|---|---|---|---|
| AutoGen | Yes (Docker) | 52.3% attack refusal rate (arXiv 2024) | No | None |
| CrewAI | No | 30.8% attack refusal rate; 65% data exfiltration success rate (arXiv 2024) | No | None |
| LangChain / LangGraph | No | Tool-level vulnerabilities (SQL injection, SSRF) documented | No | None |
| Dify | Partial | Minimal published research | No | None |
| Nexus (commercial) | Yes | N/A (platform-managed) | Yes | SOC 2 Type II, ISO 27001, ISO 42001, GDPR |
2. Governance and compliance
What to evaluate: Can you trace every decision an agent makes? Who did what, when, with what data, and why?
This criterion separates enterprise deployments from experiments. When an agent makes a decision that affects a customer, a financial transaction, or a compliance-sensitive process, the organization needs to know exactly what happened — not in theory, but in an auditable, reportable, legally defensible way.
Questions to ask:
- Does the framework provide built-in audit trails for every agent action?
- Can you trace the data that informed each decision?
- Does the framework support role-based access controls (who can create, edit, deploy agents)?
- Is there built-in version control for agent configurations?
- Can the compliance team audit agent behavior without reading source code?
The enterprise gap: No open-source agent framework provides built-in governance. Audit trails, decision traceability, access controls, and version management are all your team's responsibility. For a single prototype, this is manageable. For dozens of agents across multiple teams, it is a major engineering project that requires ongoing maintenance.
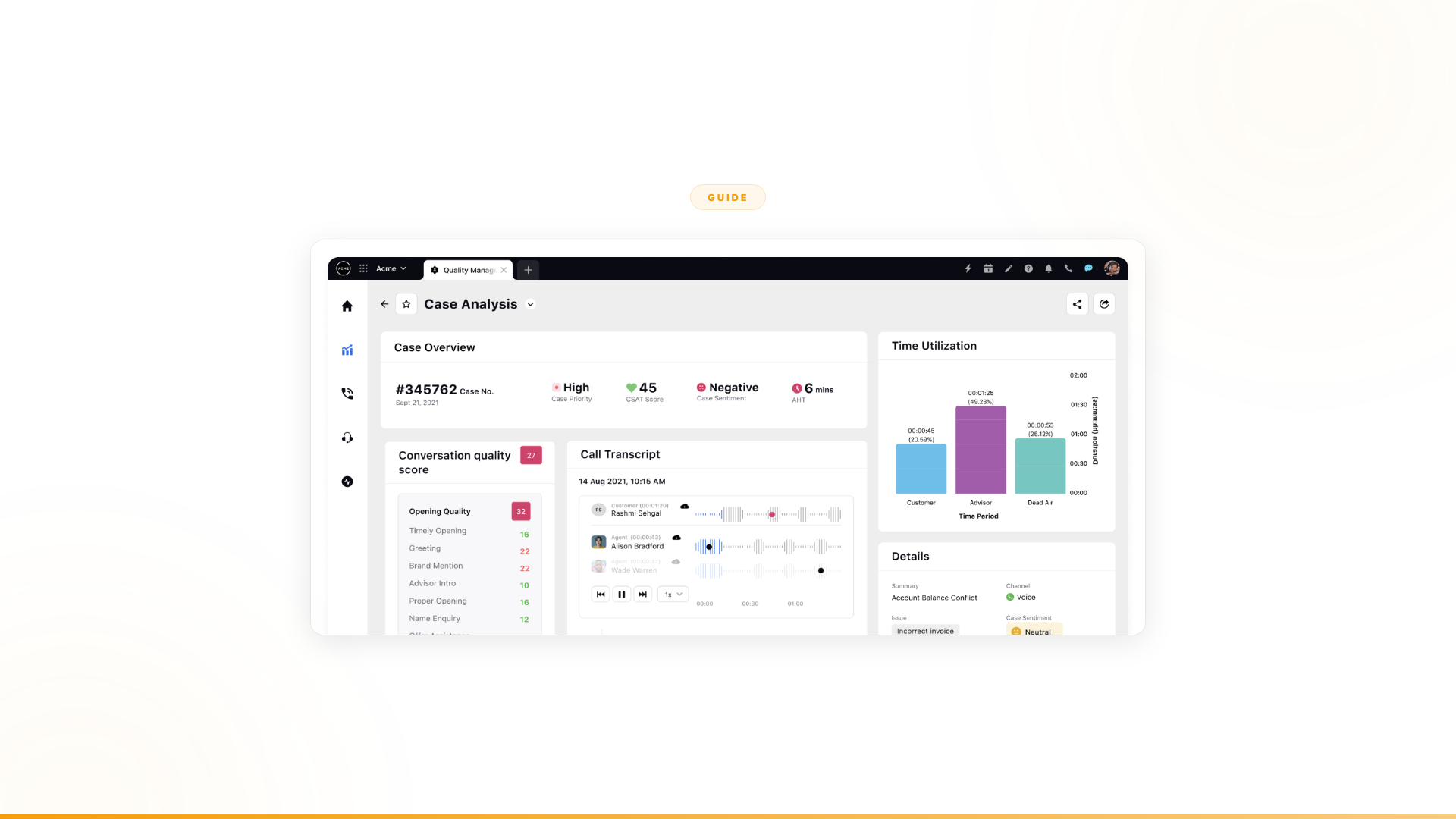
At Orange (120,000+ employees), governance was non-negotiable. Every agent decision on the Nexus platform is automatically logged and traceable. When the agent is confident, it approves. When uncertain, it escalates with full context. Every step is visible, with 100% compliance from day one — not because the team built audit infrastructure on top, but because governance is built into the platform itself.
3. Integration depth and breadth
What to evaluate: How many enterprise systems can your agent connect to, and how much engineering effort does each connection require?
Production agents do not work in isolation. A customer onboarding agent might need to read from a CRM, check against a compliance database, write to an ERP, send notifications via email and Slack, and update a reporting dashboard. That is five integrations for one agent.
Questions to ask:
- How many pre-built integrations does the framework or platform provide?
- Are integrations community-maintained or vendor-maintained?
- What is the SLA on integration reliability and updates?
- When an API changes, who updates the integration?
- Can you add custom integrations, and how much effort does that require?
Integration comparison:
| Tool | Pre-built integrations | Maintained by | SLA |
|---|---|---|---|
| AutoGen | Custom code only | Your team | N/A |
| CrewAI | Limited (growing) | Community / CrewAI | None |
| LangChain / LangGraph | Hundreds (community) | Community / LangChain | None |
| Dify | Dozens | Dify team | Basic |
| Nexus (commercial) | 4,000+ | Nexus team | Enterprise SLA |
The enterprise gap: Community-maintained integrations work well for prototyping but are unreliable for production. When a CRM updates its API and a community-built connector breaks, there is no SLA for when it gets fixed. Your options are: fix it yourself, wait for the community, or accept downtime. Enterprise platforms maintain integrations professionally, with SLAs and proactive updates when APIs change.
4. Who builds the agents
What to evaluate: Does the framework restrict agent building to engineers, or can business teams participate?
This criterion determines how fast your organization scales AI agent deployment and whether engineering becomes the permanent bottleneck.
Questions to ask:
- Can non-engineers build agents on this framework or platform?
- What technical skills are required to create, modify, and deploy an agent?
- If a business process changes, who updates the agent?
- How long does it take to go from "we need an agent for this process" to a deployed agent?
The enterprise gap: Every major open-source framework requires technical users. AutoGen requires Python expertise and multi-agent conversation design. CrewAI requires Python. LangChain and LangGraph require Python. If only engineers can build agents, engineering capacity becomes the ceiling for AI transformation.
According to a 2025 Shakudo analysis of enterprise AI agent adoption (Top 9 AI Agent Frameworks, March 2026), the developer experience gap is one of the primary reasons enterprises stall after initial prototypes — business teams cannot contribute, and engineering queues create friction that slows deployment to a crawl.
The question is not whether your engineers can build agents. It is whether everyone who needs agents can build them without waiting in the engineering backlog.
5. Consistency at scale
What to evaluate: What happens when 15 teams across your organization build agents? Do they all work the same way?
This criterion is invisible when evaluating a framework with one prototype. It becomes the dominant challenge at enterprise scale.
Questions to ask:
- Does the framework enforce architectural standards across agents?
- Is error handling consistent across all agents, or does each builder implement their own approach?
- Is logging standardized so you can monitor all agents from one dashboard?
- When one agent is improved, do other agents benefit?
- Can you update all agents simultaneously, or must each be updated individually?
The enterprise gap: Open-source frameworks provide flexibility, which is the opposite of consistency. When each developer makes independent decisions about error handling, logging, security patterns, and escalation logic, the result is a portfolio of unique agents that cannot be monitored, audited, or maintained systematically.
Enterprise platforms enforce consistency structurally. Every agent built on a platform inherits the same architectural patterns, the same logging framework, the same security model. Consistency is not a goal you manage. It is an outcome that is automatic.
6. Time to production value
What to evaluate: How long from project kickoff to agent in production delivering measurable business outcomes?
Not time to prototype. Time to production. Most framework-based projects deliver a convincing prototype in weeks, then spend months bridging to production.
Questions to ask:
- What is the realistic timeline from project start to first production agent?
- How much of that timeline is framework-related versus infrastructure, security, compliance, and integration work?
- What is the total engineering cost (team size multiplied by months)?
- When does the business start seeing measurable ROI?
Typical timelines:
| Approach | Prototype | Production (first agent) | Enterprise scale |
|---|---|---|---|
| Open-source framework | 1–2 weeks | 3–6 months | 12+ months |
| Enterprise platform (Nexus) | 1–2 weeks | 4 weeks | 3–6 months |
The enterprise gap: The prototype-to-production gap is where most framework-based projects stall. The framework handles agent logic. The other 80% — deployment, monitoring, security, integrations, exception handling, governance, testing — requires sustained engineering effort. Orange deployed production agents on Nexus in 4 weeks. With a framework, that timeline would be months, assuming dedicated engineering capacity.
7. Total cost of ownership
What to evaluate: What is the real cost over 12 months, including engineering time, infrastructure, maintenance, and opportunity cost?
Open-source software is free. Open-source enterprise deployments are not.
Questions to ask:
- How many engineers are needed full-time for the first production agent?
- What is the ongoing maintenance burden per agent?
- What infrastructure costs are required (hosting, monitoring, logging, security)?
- What is the opportunity cost of engineering time diverted from your core product?
- How does cost scale as you add more agents?
Cost comparison (illustrative 12-month estimate, single department):
| Cost category | Open-source framework | Enterprise platform (Nexus) |
|---|---|---|
| Software license | $0 | Per-agent pricing |
| LLM API costs | $5,000–50,000 | Included or comparable |
| Engineering (build) | 2–4 engineers × 3–6 months | Forward Deployed Engineer embedded |
| Engineering (maintain) | 0.5–1 engineer ongoing | Platform-managed |
| Infrastructure | $2,000–10,000/month | Platform-managed |
| Compliance / governance | 1–2 months engineering | Built-in |
| Integration development | 1–3 months per major integration | 4,000+ pre-built |
| Total engineering cost | $300K–800K+ first year | Platform fee tied to value |
| Time to measurable ROI | 6–12 months | 4–8 weeks |
Engineering cost estimates are Nexus internal benchmarks based on observed client deployments. Actual costs vary by team size, existing infrastructure, and compliance requirements.
The opportunity cost calculation matters beyond the direct engineering line item. Every senior engineer building framework infrastructure is an engineer not building your core product. For companies where engineering is a competitive differentiator, that trade-off deserves explicit scrutiny.
8. Support model and organizational change
What to evaluate: When things go wrong, what support is available? And who handles the organizational change required to drive adoption?
This criterion is consistently underweighted during technical evaluation and consistently becomes the primary determinant of success or failure.
Questions to ask:
- When agents fail in production, what support is available?
- What is the response time for critical issues?
- Who helps identify the highest-impact use cases for your organization?
- Who handles change management and adoption across business teams?
- What expertise is available for complex integration scenarios?
The enterprise gap: Open-source support is community-based: GitHub issues, Discord channels, documentation. For individual developers, this works. For enterprise teams deploying agents across business-critical processes, community support is not sufficient.
Nexus embeds Forward Deployed Engineers (FDEs) with your organization — engineers who work alongside your team to identify the highest-impact use cases, design agents for your specific reality, handle integration complexity, and drive adoption. FDEs also manage the transition from ad-hoc development to systematic agent deployment. That transition is where most enterprise AI initiatives stall.
Deploying AI agents at enterprise scale is 10% technology and 90% organizational change. That organizational change does not come from a GitHub repository.
The decision framework
After working through all eight criteria, most enterprises land in one of three categories:
Category A: Open-source is the right choice
You have dedicated AI engineering capacity (3+ engineers not needed for your core product). You are deploying single-digit agents. Your compliance requirements are minimal or your team is prepared to build compliance infrastructure. Your timeline can absorb 6+ months for the first production agent. Your primary goal is technical learning or building something no platform supports.
Recommendation: Evaluate CrewAI for multi-agent orchestration, AutoGen for secure code-executing agents, LangGraph for complex stateful workflows. All three have active communities and growing enterprise adoption.
Category B: Hybrid approach
You want to experiment with open-source for prototyping and research, but need a production-grade platform for enterprise deployment. Some teams explore new use cases with frameworks. Production agents run on a platform.
Recommendation: Use open-source frameworks for exploration. Deploy production agents on an enterprise platform with governance, compliance, and support.
Category C: Enterprise platform from day one
You need business teams — not just engineers — building and owning agents. Governance and compliance are non-negotiable. You need production agents delivering financial outcomes in weeks, not months. You will deploy dozens of agents across multiple departments. Your engineering capacity is better spent on your core product.
Recommendation: Skip the framework evaluation. The framework is 20% of the work. Start with a platform that delivers the full 100%.
What Category C looks like in practice
Orange Group (multi-billion euro telecom): Business team deployed customer onboarding agents on Nexus in 4 weeks. 50% conversion improvement. ~$6M+ yearly revenue. 90% autonomous resolution. 100% team adoption. Every agent decision logged and auditable. No engineering dependency.
European telecom (13,000+ employees): Previously spent 6 months with Copilot Studio without delivering a single production use case. Deployed a dozen Nexus agents. 40% support volume freed across millions of interactions.
100% POC-to-contract conversion rate across all Nexus engagements. Every proof of concept tied to measurable outcomes. Forward Deployed Engineers embedded from day one.
The summary checklist
Use this checklist to evaluate any open-source AI agent framework for enterprise use:
| Criterion | Question | Open-source reality | Enterprise platform reality |
|---|---|---|---|
| Security | Is it secure by default? | No. Security is opt-in. Your team builds it. | Yes. SOC 2, ISO 27001, ISO 42001, GDPR built in. |
| Governance | Can you audit every agent decision? | No. Your team builds audit trails. | Yes. Automatic audit trails and decision traceability. |
| Integrations | How many systems can agents connect to? | Community-built, variable quality, no SLA. | 4,000+ maintained integrations with enterprise SLAs. |
| Builder access | Can non-engineers build agents? | No. Requires Python or terminal skills. | Yes. Business teams build and own agents. |
| Consistency | Are agents architecturally consistent? | No. Each builder makes independent decisions. | Yes. Platform enforces consistency structurally. |
| Time to value | When does the business see ROI? | 6–12 months for first production agent. | 4–8 weeks for measurable outcomes. |
| Total cost | What is the real 12-month cost? | $300K–800K+ (engineering + infrastructure). | Platform fee tied to value delivered. |
| Support | Who helps when things go wrong? | Community (GitHub issues, Discord). | Forward Deployed Engineers embedded with your team. |
Frequently asked questions
What are the leading open-source AI agent frameworks in 2025?
The most actively developed open-source frameworks are AutoGen (Microsoft, sandboxed execution, event-driven architecture in v0.4), CrewAI (multi-agent collaboration, 100,000+ trained developers, strong for role-based pipelines), LangGraph (graph-based stateful orchestration, used in production by Klarna and Replit), and Dify (LLM application development with a visual interface). Each has different strengths: AutoGen for secure code-executing agents, CrewAI for multi-agent role orchestration, LangGraph for complex conditional workflows.
What are the real security risks in open-source AI agent frameworks?
Independent research published on arXiv (December 2024) tested AutoGen and CrewAI across 13 attack scenarios. More than half of malicious prompts succeeded across all configurations (41.5% overall refusal rate). CrewAI on GPT-4o was successfully manipulated into exfiltrating private data 65% of the time. The OWASP Top 10 for LLM Applications (2025) identifies prompt injection as the leading risk. The root causes are largely framework-agnostic: poorly scoped prompts, missing input validation, and overly permissive tool access. These are configuration and deployment problems your team must address regardless of which framework you choose.
Do open-source AI agent frameworks meet enterprise compliance requirements?
No open-source framework ships with SOC 2 Type II, ISO 27001, or GDPR certification. These certifications require organizational processes, audit infrastructure, and continuous compliance monitoring built on top of the framework by your team. For regulated industries (finance, healthcare, telecommunications), the compliance build typically adds 1–2 months of dedicated engineering effort before the first agent reaches production.
What is the difference between AutoGen and CrewAI for enterprise use?
AutoGen (Microsoft) provides sandboxed Docker execution, making it more secure by default for code-executing agents. In independent security research, AutoGen showed a higher attack refusal rate (52.3%) than CrewAI (30.8%). CrewAI focuses on multi-agent collaboration with defined roles and task assignment, making it stronger for pipeline orchestration where multiple specialized agents hand off work. Neither framework provides enterprise governance, compliance certifications, or production support SLAs.
When should an enterprise choose open-source over a commercial platform?
Open-source is the stronger choice when your team has 3+ dedicated AI engineers available for framework build and ongoing maintenance, your compliance requirements are limited (no mandatory SOC 2 or ISO 27001), the use case is internal-facing rather than customer-facing, and your primary goal is deep customization or building something no existing platform supports. For enterprises that need business teams to own agents, need production timelines measured in weeks, or operate in regulated industries, the framework build cost typically outweighs the flexibility benefit.
Worth exploring?
If your evaluation is pointing toward Category C, every Nexus engagement starts with a 3-month proof of concept tied to measurable outcomes. Forward Deployed Engineers embed with your team from day one. You see the results before committing. You can exit anytime.
See how Nexus compares to open-source frameworks →
Related reading
- Nexus vs AutoGen: platform vs research framework
- Nexus vs CrewAI: enterprise agents vs multi-agent framework
- Nexus vs LangChain: platform vs developer framework
- Top 10 open-source AI agent frameworks for enterprise
- AutoGen vs CrewAI: open-source frameworks compared
- How to automate business workflows with AI agents
External sources cited in this article:
- Penetration Testing of Agentic AI: A Comparative Security Analysis Across Models and Frameworks — arXiv, December 2024
- OWASP Top 10 for LLM Apps & Gen AI, Version 1.0, February 2025
- Top 9 AI Agent Frameworks as of March 2026 — Shakudo
- AI Agents Are Here. So Are the Threats. — Palo Alto Networks Unit 42